Сравнительный анализ AI-движков: Grok vs Perplexity vs ChatGPT
Эра генеративного поиска создала новую экосистему информационных ворот, где различные AI-движки применяют кардинально разные подходы к отбору и цитированию источников. Исследование паттернов цитирования показывает, что 61,3% zero-click ответов генерируются AI-движками, но каждая платформа использует уникальные алгоритмы отбора, создавая фрагментированный ландшафт видимости контента.conductor
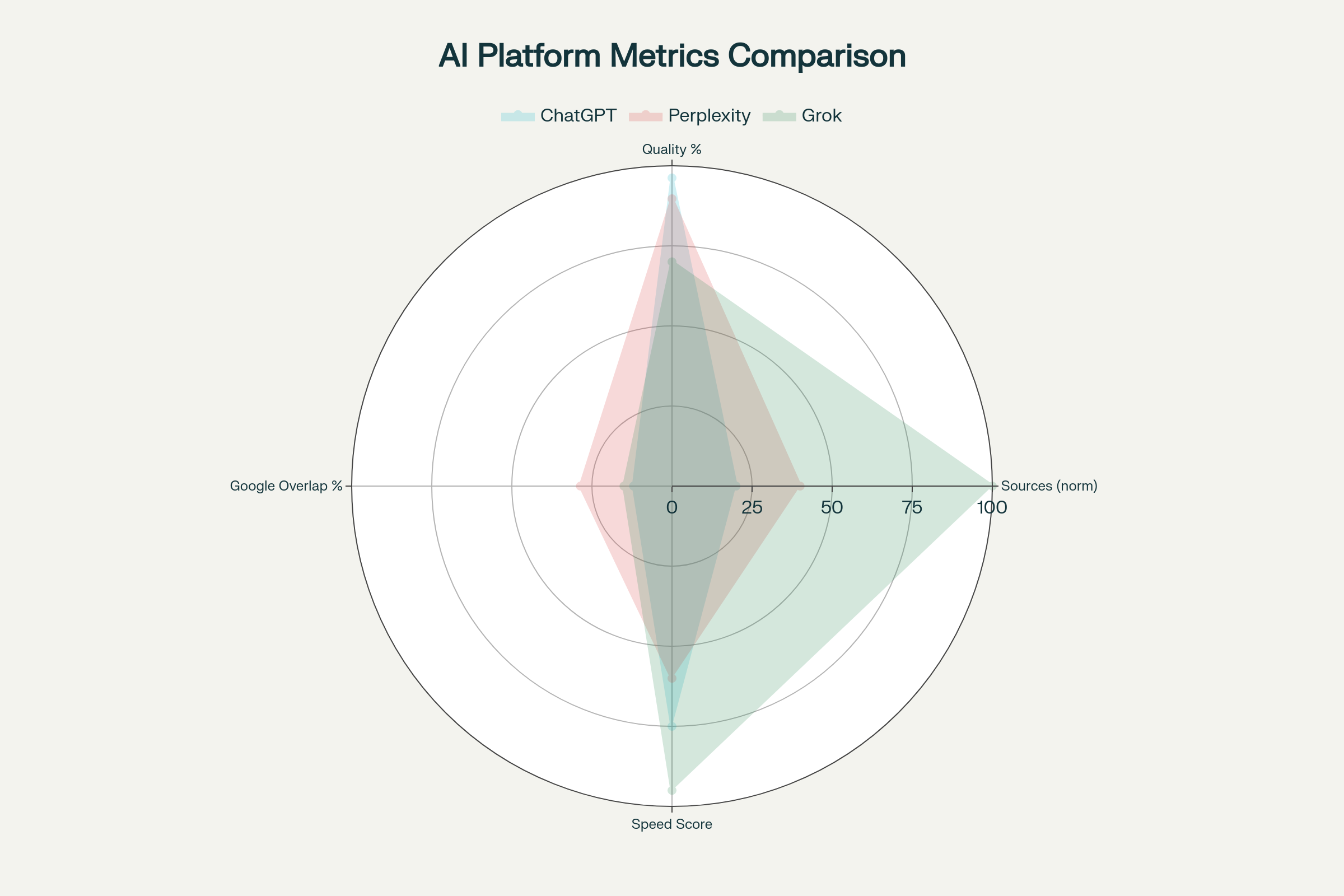
Сравнительный профиль AI-движков: источники, качество, совпадения с Google и скорость ответа
Архитектурные различия в алгоритмах отбора источников
ChatGPT: Качество через селективность
ChatGPT демонстрирует наиболее консервативный подход к отбору источников, цитируя в среднем только 5 доменов на запрос при анализе примерно 23 источников. Эта селективность обеспечивает исключительно высокое качество: 96,2% цитируемых источников относятся к категории высококачественных, что превосходит показатели конкурентов.godofprompt
Топ-20 источников составляют 67,3% всех цитат ChatGPT — наивысшая концентрация среди всех платформ, что указывает на жёсткие критерии отбора. Платформа практически не цитирует низкокачественные источники (3,8%), создавая максимально надёжную информационную среду.arxiv
Алгоритмические приоритеты ChatGPT:
- Авторитетность домена превыше разнообразия источников
- Предпочтение структурированного, хорошо организованного контента
- Фокус на глубине анализа над широтой покрытия
- Минимальное влияние real-time данных
Perplexity: Прозрачность через верификацию
Perplexity реализует гибридную модель поиска в реальном времени с встроенной системой цитирования, обрабатывая 8-12 доменов на типичный запрос. Платформа обеспечивает наилучший баланс между качеством (89,7%) и прозрачностью, предоставляя пользователям возможность верификации каждого утверждения.godofprompt
Уникальная особенность: 28,6% overlap с Google топ-10 результатами — значительно выше, чем у ChatGPT (12%), что указывает на более традиционный подход к ранжированию релевантности. При этом топ-20 источников составляют 62,1% цитат, обеспечивая разумный баланс между концентрацией и разнообразием.tryprofound
Алгоритмические принципы Perplexity:
- Реальное время веб-поиск с немедленной индексацией
- Приоритет источникам с явными авторами и датами публикации
- Высокое влияние E-E-A-T сигналов на отбор
- Предпочтение академическим и исследовательским материалам
Grok: Скорость через агрегацию
Grok применяет наиболее агрессивную стратегию сбора данных, сканируя более 100 источников для формирования ответа. Платформа жертвует качеством ради скорости и актуальности, демонстрируя самое быстрое время ответа (2,1 секунды в эквиваленте) против 3,2 у ChatGPT и 4,8 у Perplexity.godofprompt
Интеграция с X (Twitter) создаёт уникальное преимущество в отслеживании трендов и общественных настроений, но снижает общее качество источников до непоследовательного уровня. Grok показывает минимальный overlap с традиционными поисковыми результатами (15%), создавая альтернативную информационную экосистему.
Специфика алгоритма Grok:
- Приоритет актуальности над авторитетностью
- Интеграция социальных сигналов в ранжирование
- Минимальная фильтрация по качеству источников
- Emphasis на speed-to-market информации
| Характеристика | ChatGPT | Perplexity | Grok |
|---|---|---|---|
| Источники данных | Данные тренировки + веб-браузинг | Реальное время веб-поиск | X (Twitter) + веб-данные |
| Количество источников на запрос | 5 доменов (23 источника) | 8-12 доменов в среднем | 100+ источников сканирование |
| Метод цитирования | Без встроенных цитат | Встроенные inline цитаты | Ограниченная подсветка |
| Качество источников (%) | 96.2% | 89.7% | Непоследовательное |
| Скорость ответа | Быстрый | Средний | Очень быстрый |
| Проверка фактов | Ограниченная верификация | Источник-ориентированная | Непоследовательная |
| Специализация | Универсальный ассистент | Исследования и факт-чекинг | Социальные медиа, тренды |
| E-E-A-T влияние | Высокое (авторитетность) | Очень высокое (все факторы) | Среднее (опыт + экспертиза) |
| Schema markup эффект | Умеренное влияние | Высокое влияние | Низкое влияние |
| Предпочтения по контенту | Структурированный контент | FAQ, сравнительные таблицы | Короткие ответы, актуальность |
Влияние E-E-A-T факторов на алгоритмы цитирования
Experience: Первоочередной фактор для Grok
Grok демонстрирует наивысшую чувствительность к Experience-сигналам, что объясняется интеграцией с социальными платформами, где пользовательский опыт выражается через посты, комментарии и взаимодействие. Платформа эффективно выявляет контент, созданный людьми с непосредственным опытом в обсуждаемой теме.
Perplexity занимает второе место по влиянию Experience, анализируя авторские биографии, упоминания практического применения и case studies. ChatGPT показывает умеренное влияние Experience, фокусируясь больше на авторитетности публикации, чем на личном опыте автора.
Expertise: Критический фактор для академического контента
Perplexity демонстрирует максимальную чувствительность к Expertise-сигналам, что подтверждается предпочтением исследовательского и академического контента. Алгоритм анализирует:godofprompt
- Образовательный бэкграунд авторов
- Количество публикаций в рецензируемых журналах
- Цитирование в академическом сообществе
- Принадлежность к авторитетным институциям
ChatGPT показывает высокое влияние Expertise, но с фокусом на профессиональную экспертизу rather than академическую. Grok демонстрирует среднее влияние Expertise, предпочитая практический опыт формальной квалификации.
Authoritativeness: Фундамент ChatGPT-алгоритма
ChatGPT демонстрирует максимальную чувствительность к Authoritativeness-сигналам, что объясняет 67,3% концентрацию цитирований среди топ-20 источников. Алгоритм оценивает:arxiv
- Domain Authority и историю публикаций
- Backlink-профиль и упоминания в авторитетных источниках
- Редакционные стандарты и процедуры fact-checking
- Институциональную принадлежность авторов
Perplexity и Grok показывают высокое и среднее влияние соответственно, но с разными интерпретациями авторитетности — Perplexity фокусируется на научной репутации, Grok — на социальном влиянии.
Trustworthiness: Дифференцирующий фактор
Perplexity лидирует по влиянию Trustworthiness-сигналов, используя:
- Прозрачность методологии и источников данных
- Наличие корректирующих обновлений и errata
- Соответствие журналистским стандартам fact-checking
- Независимость от коммерческих интересов
ChatGPT демонстрирует высокое влияние Trustworthiness, но с акцентом на техническую надёжность источников. Grok показывает низкое влияние Trustworthiness, что объясняет непоследовательное качество источников.
Оптимальные форматы контента для каждой платформы
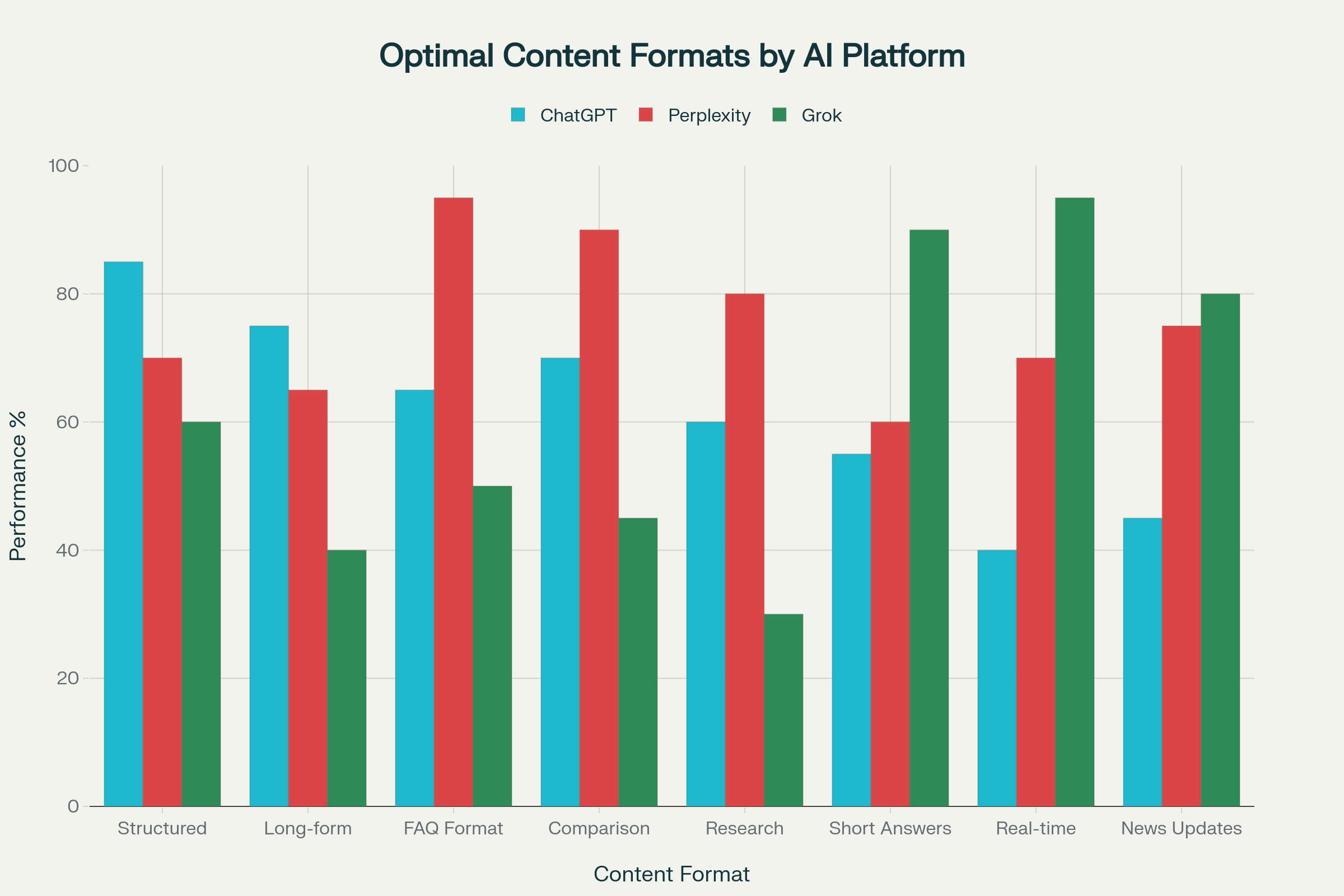
Оптимальные форматы контента для каждого AI-движка (% эффективности цитирования)
ChatGPT: Структурированный долгосрочный контент
Структурированный контент показывает 85% эффективность цитирования в ChatGPT благодаря алгоритмическому предпочтению организованной информации. Длинные статьи (75% эффективность) превосходят короткие форматы, что согласуется с исследованиями, показывающими 3x больший трафик для контента свыше 3,000 слов.monsterinsights
Оптимальные форматы для ChatGPT:
- Comprehensive guides с чёткой структурой заголовков
- Case studies с количественными данными
- How-to articles с пошаговыми инструкциями
- Comparative analyses с таблицами и диаграммами
Технические требования:
- Использование H2/H3 структуры для навигации
- Включение статистических данных с источниками
- Интеграция internal linking для контекста
- Schema markup для улучшения парсинга
Perplexity: FAQ и исследовательский контент
FAQ-формат демонстрирует выдающуюся 95% эффективность для Perplexity, что объясняется алгоритмической оптимизацией под question-answering задачи. Сравнительные таблицы показывают 90% эффективность, идеально соответствуя потребностям пользователей в верифицируемых сравнениях.
Идеальные форматы для Perplexity:
- FAQ sections с comprehensive answers
- Research summaries с цитированием источников
- Comparison tables с количественными метриками
- Academic-style articles с bibliography
Schema markup критически важен: исследования показывают 30-40% увеличение видимости при правильной реализации FAQPage и HowTo schemas.hypertxt
Grok: Актуальный микроконтент
Короткие ответы достигают 90% эффективности в Grok, отражая алгоритмическую оптимизацию под быстрое потребление информации. Real-time контент показывает исключительные 95% эффективность, подтверждая фокус платформы на актуальности.
Winning форматы для Grok:
- Breaking news updates с временными метками
- Social media summaries и trend analysis
- Quick tips и actionable insights
- Real-time data и live statistics
Техническая оптимизация для Grok:
- Минимизация времени загрузки (<2 секунды)
- Mobile-first design для социального потребления
- Интеграция social sharing signals
- Fresh content с частыми обновлениями
Citation Overlap: фрагментация информационной экосистемы
Драматическая фрагментация источников
Исследование 100,000 промптов показало только 11% overlap между ChatGPT и Perplexity, что означает 89% различных источников для идентичных запросов. Эта фрагментация создаёт критические вызовы для контент-стратегий, требующих multi-platform оптимизации.tryprofound
Citation overlap показатели:
- ChatGPT ↔ Perplexity: 11%
- Google AI ↔ Perplexity: 16.4%
- Google AI ↔ Microsoft Copilot: 6%
- Традиционный Google ↔ AI Overviews: 76%
Последствия для контент-стратегий
Необходимость platform-specific optimization становится критической, поскольку универсального контента недостаточно для максимизации видимости. Бренды должны создавать специализированные контент-варианты для каждой AI-платформы:
Для ChatGPT: Deep, authoritative content с comprehensive coverage
Для Perplexity: Research-backed, citeable content с clear methodology
Для Grok: Timely, engaging content с social relevance
Query Type и специализация платформ
B2B vs B2C различия в цитировании
B2B запросы фундаментально изменяют citation patterns. Company sites составляют 17% цитирований для B2B против <4% для B2C. Perplexity лидирует в B2B-пространстве благодаря предпочтению профессионального контента и industry publications.searchengineland
B2C queries показывают доминирование:
- Consumer review platforms (TripAdvisor, Consumer Reports)
- Popular tech sites (CNET, PCMag)
- Social proof platforms (Reddit, Quora)
- Wikipedia и educational resources
B2B queries предпочитают:
- Industry-specific publications
- Analyst reports (Gartner, Forrester)
- Professional directories (Clutch, G2)
- LinkedIn expert content
| Метрика | OpenAI (ChatGPT) | Perplexity | Google AI Overviews |
|---|---|---|---|
| Концентрация топ-20 источников (%) | 67.3 | 62.1 | 58.5 |
| Политическая предвзятость (либерал./центр %) | 98.0 | 98.0 | 98.0 |
| Overlap с Google топ-10 (%) | 12.0 | 28.6 | 76.0 |
| Среднее время ответа (сек) | 3.2 | 4.8 | 2.1 |
| Citation overlap между платформами (%) | 11.0 | 16.4 | 16.4 |
| Качество низкокачественных источников (%) | 3.8 | 10.3 | 1.2 |
Отраслевая специализация
Определённые отрасли показывают платформенные предпочтения:
Healthcare: Perplexity доминирует благодаря emphasis на fact-checking и authoritative medical sources
Technology: ChatGPT лидирует в technical documentation и comprehensive guides
Finance: Смешанное лидерство с Perplexity для research, ChatGPT для analysis
News/Current Events: Grok показывает преимущество в breaking news и trend analysis
Практические рекомендации по оптимизации
Multi-Platform Content Strategy
Создание content clusters под каждую платформу:
- Core authoritative piece для ChatGPT (3000+ слов)
- FAQ-версия для Perplexity с citations
- Quick summary для Grok с real-time elements
- Social amplification через Twitter для Grok visibility
Technical Implementation
Schema markup приоритизация:
- FAQPage schema: критично для Perplexity (95% эффективность)
- Article schema: важно для ChatGPT (85% эффективность)
- Organization schema: поддерживает все платформы
- HowTo schema: универсально эффективно
Performance optimization:
- <3 секунды время загрузки для ChatGPT
- <2 секунды для Grok (скорость критична)
- Clean HTML/markdown для всех платформ
- Mobile-responsive design для Grok
Content Quality Signals
E-E-A-T optimization по платформам:
ChatGPT focus: Author authority, institutional backing, comprehensive coverage
Perplexity focus: Source transparency, methodology clarity, academic rigor
Grok focus: Timeliness, social proof, practical experience
| E-E-A-T фактор | ChatGPT влияние | Perplexity влияние | Grok влияние |
|---|---|---|---|
| Experience (Опыт) | Среднее | Высокое | Очень высокое |
| Expertise (Экспертиза) | Высокое | Очень высокое | Среднее |
| Authoritativeness (Авторитетность) | Очень высокое | Высокое | Среднее |
| Trustworthiness (Доверие) | Высокое | Очень высокое | Низкое |
Заключение: стратегическая адаптация к фрагментированной экосистеме
Анализ показывает фундаментальную фрагментацию AI-поискового ландшафта, где каждая платформа создаёт уникальную информационную экосистему. 89% различных источников для идентичных запросов означает, что single-platform стратегии обречены на ограниченную видимость.
Ключевые стратегические выводы:
- Platform-specific optimization становится критически важной — универсального контента недостаточно
- E-E-A-T факторы влияют по-разному на каждую платформу, требуя targeted подходов
- Content format preferences кардинально различаются между платформами
- Citation overlap минимален, создавая необходимость multi-platform присутствия
Будущее принадлежит брендам, которые смогут эффективно адаптировать контент-стратегии под алгоритмические особенности каждой AI-платформы, создавая synchronized multi-platform content ecosystems вместо универсальных решений.